2
14
23
新手上路
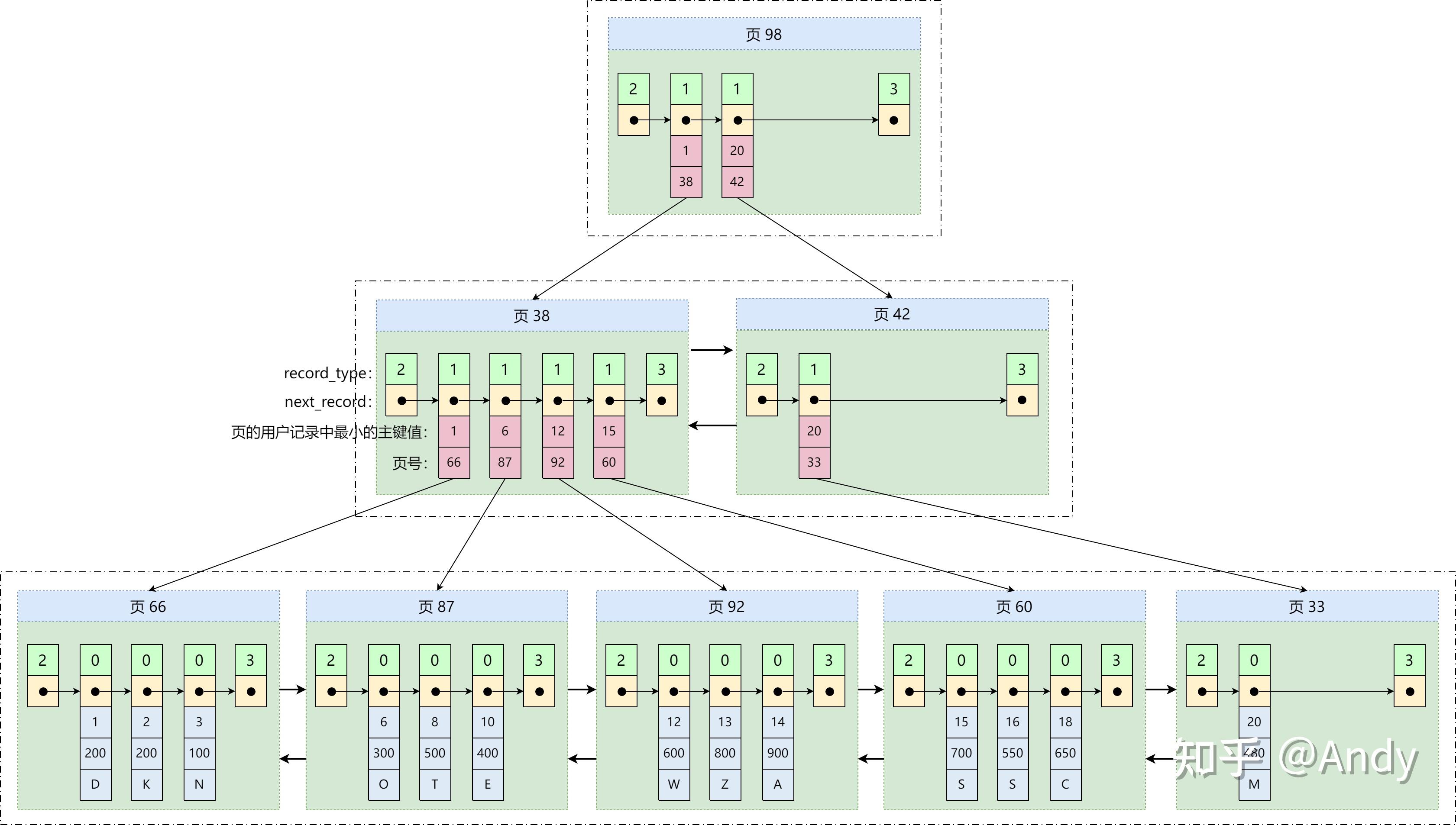
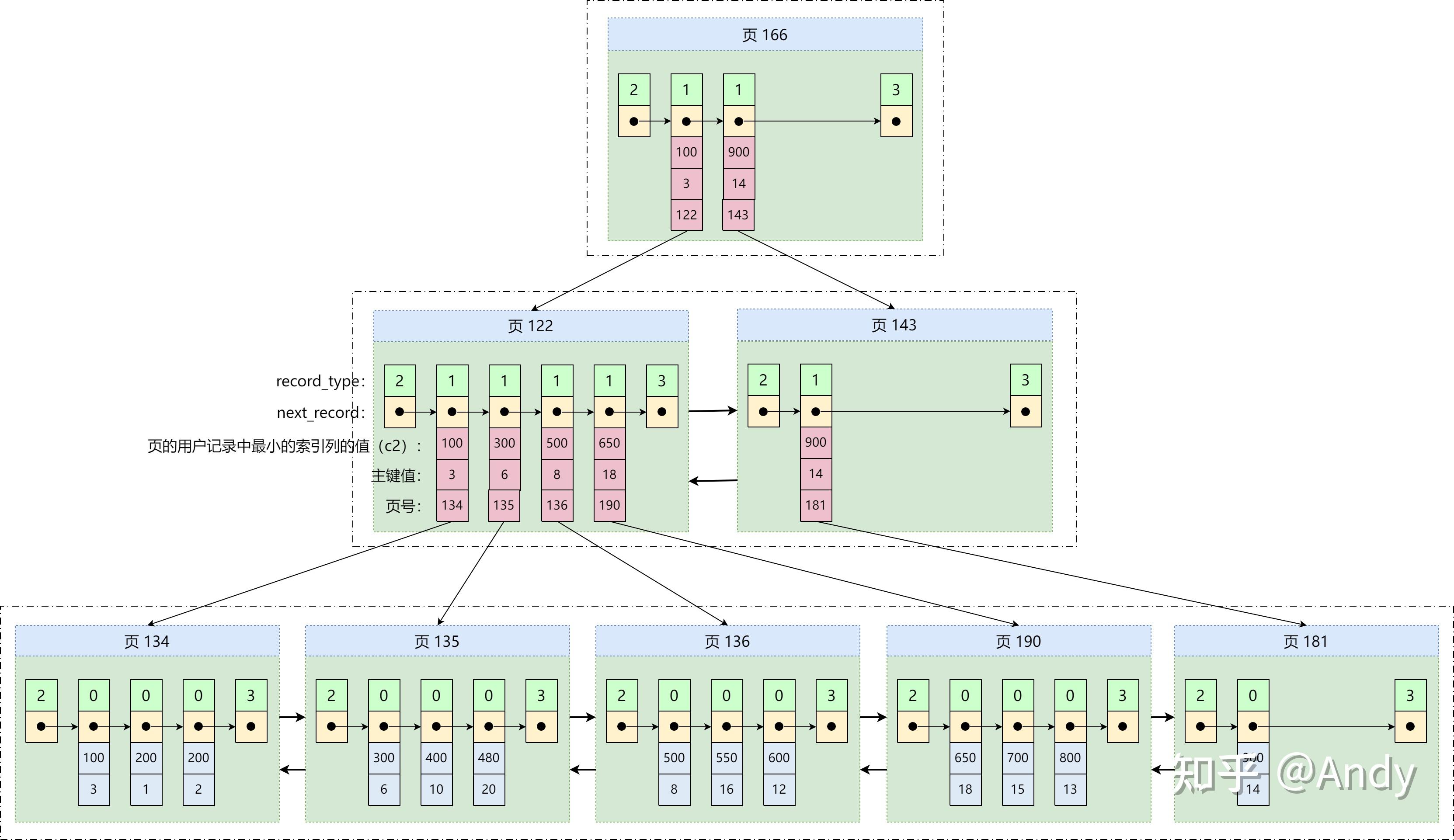
本篇文章主要胡侃一下 MySQL 中的索引,重点剖析了 InnoDB 存储引擎的 B+ 树 首先,在索引概述中,介绍了索引是什么?有哪些特点?是怎么分类的?然后,通过一个示例,剖析了聚集索引和非聚集索引的结构、特点。最后,总结了 MySQL 中一些索引失效的场景、设计索引的原则等实践应用
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver手机版
Powered by Discuz! X3.4© 2001-2015 Comsenz Inc.



 发表于 2023-6-2 14:32:26
发表于 2023-6-2 14:32:26