|
|
我对老师的代码有所修改,没有输出图,实现了最基本的功能
1. 流程图
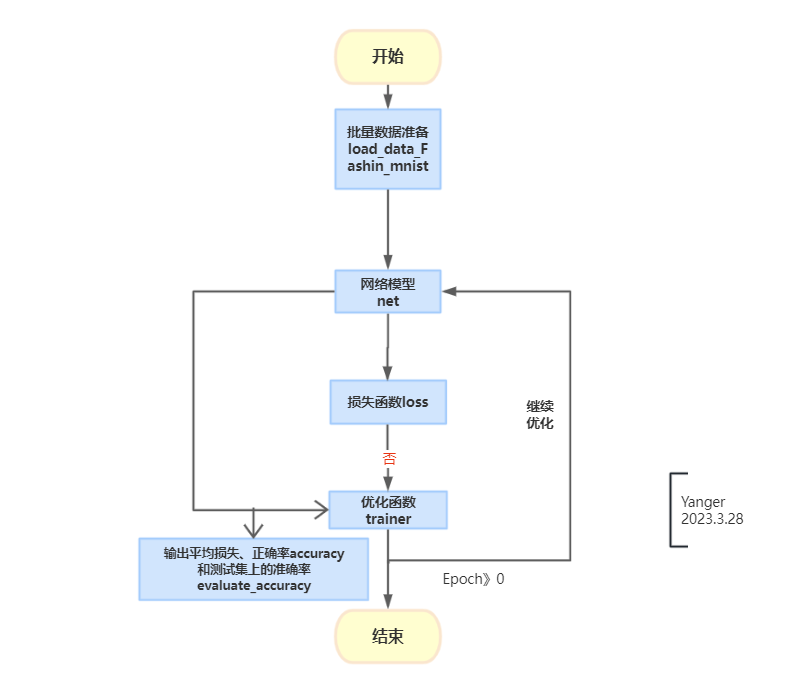
2. 数据准备
import torch
import torchvision.datasets
from torch import nn
from torchvision import transforms
from torch.utils import data
# 数据
def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=0),
data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=0))
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
- num_workers是进程数,我的电脑只能是0,不然报错
- trans是个list,里面第一个参数就是:[transforms.ToTensor()],来实现图像转torch的tensor格式;如果有resize,那么会在0号位置插上transforms.Resize(resize),实现图像像素的变形。即此时trans = [transforms.Resize(resize),transforms.ToTensor()]两条规则
- transform=transforms.Compose(trans) 会把图像相应的按照list里的1条规则或者两条规则 进行相应的转化
3. net模型
# 初始化模型参数
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
#
#
def init_weights(m):
if m == nn.Linear:
# 默认 mean=0 std
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
4. 损失函数
loss = nn.CrossEntropyLoss(reduction="none")
- reduction="none" 是不做处理,那么这里loss是一批数据的loss和;此处还能reduction="mean",直接算均值。我们因为要求所有数据的和/所有数据数,所以在这里没有求批量数据的均值
它包含了3.6从零实现的两部分内容:
- softmax(net(X))进行softmax
- CrossEntropyLoss(softmax(net(X)),y)计算损失
我们可以认为nn.CrossEntropyLoss(reduction="none")已经封装了softmax()
nn.CrossEntropyLoss()=nn.log_softmax() + nn.NLLLoss()
所以不用在net(X)里面增加softmax层了

5. 优化
trainer = torch.optim.SGD(net.parameters(), lr=0.01)6 评估
class Accumulator:
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def train_epoch_ch3(net, train_iter,loss, updater):
if isinstance(net, torch.nn.Module):
net.train()
metric = Accumulator(3)
for X,y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad()
l.mean().backward()
updater.step()
else:
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()),accuracy((y_hat), y),y.numel())
return metric[0]/metric[2],metric[1]/metric[2]
#
#
#
def accuracy(y_hat,y): #@save
if len(y_hat.shape)>1 and y_hat.shape[1]>1:
# 哪一项是最大的
y_hat = y_hat.argmax(axis =1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter): #@save
if isinstance(net, torch.nn.Module):
net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X,y in data_iter:
metric.add(accuracy(net(X),y),y.numel())
return metric[0]/metric[1]
- class Accumulator是个容器,我们要求整体数据的loss 争取数据的个数,所以要找个地方,把每批的情况累加起来
- def accuracy 是有多少个数据通过net网络结果和答案是一致的
- train_epoch_ch3 每轮下来,训练数据的平均损失和正确率,用到了def accuracy
- evaluate_accuracy 是测试集的正确率,用到了def accuracy
- 训练的时候,用训练模式net.train(),更新的时候,之前梯度要清0;测试的时候要用测试模式net.eval()
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
for epoch in range(num_epochs):
train_loss, train_acc = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
print("epoch", epoch + 1, 'train loss', train_loss, 'train acc', train_acc, 'test acc', test_acc)
num_epochs = 10
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)- train_ch3整体打包,输出每轮学完,所有训练数据学习的情况和所有测试数据预测的情况
7. 完整代码
import torch
import torchvision.datasets
from torch import nn
from torchvision import transforms
from torch.utils import data
# 数据
def load_data_fashion_mnist(batch_size, resize=None):
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=0),
data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=0))
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
# for X,y in train_iter:
# print(X.shape,y.shape)
# break
# 初始化模型参数
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if m == nn.Linear:
# 默认 mean=0 std
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 损失函数reduction好像可以均值 可以不做处理事loss和
loss = nn.CrossEntropyLoss(reduction="none")
# 优化
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
class Accumulator:
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def train_epoch_ch3(net, train_iter,loss, updater):
if isinstance(net, torch.nn.Module):
net.train()
metric = Accumulator(3)
for X,y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad()
l.mean().backward()
updater.step()
else:
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()),accuracy((y_hat), y),y.numel())
return metric[0]/metric[2],metric[1]/metric[2]
def accuracy(y_hat,y): #@save
if len(y_hat.shape)>1 and y_hat.shape[1]>1:
# 哪一项是最大的
y_hat = y_hat.argmax(axis =1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter): #@save
if isinstance(net, torch.nn.Module):
net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X,y in data_iter:
metric.add(accuracy(net(X),y),y.numel())
return metric[0]/metric[1]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
for epoch in range(num_epochs):
train_loss, train_acc = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
print("epoch", epoch + 1, 'train loss', train_loss, 'train acc', train_acc, 'test acc', test_acc)
num_epochs = 10
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer) |
|



 发表于 2023-7-21 11:23:47
发表于 2023-7-21 11:23:47