|
|
最近有一个业务是前端要上传word格式的文稿,然后用户上传完之后,可以用浏览器直接查看该文稿,并且可以在富文本框直接引用该文稿,所以上传word文稿之后,后端保存到db的必须是html格式才行,所以涉及到word格式转html格式。
通过调查,这个word和html的处理,有两种方案,方案1是前端做这个转换。方案2是把word文档上传给后台,后台转换好之后再返回给前端。至于方案1,看到大家的反馈都说很多问题,所以就没采用前端转的方案,最终决定是后端转化为html格式并返回给前段预览,待客户预览的时候,确认格式没问题之后,再把html保存到后台(因为word涉及到的格式太多,比如图片,visio图,表格,图片等等之类的复杂元素,转html的时候,可能会很多格式问题,所以要有个预览的过程)。
对于word中普通的文字,问题倒不大,主要是文本之外的元素的处理,比如图片,视频,表格等。针对我本次的文章,只处理了图片,处理的方式是:后台从word中找出图片(当然引入的jar包已经带了获取word中图片的功能),上传到服务器,拿到绝对路径之后,放入到html里面,这样,返回给前端的html内容,就可以直接预览了。
maven引入相关依赖包如下:
<poi-scratchpad.version>3.14</poi-scratchpad.version>
<poi-ooxml.version>3.14</poi-ooxml.version>
<xdocreport.version>1.0.6</xdocreport.version>
<poi-ooxml-schemas.version>3.14</poi-ooxml-schemas.version>
<ooxml-schemas.version>1.3</ooxml-schemas.version>
<jsoup.version>1.11.3</jsoup.version>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>${poi-scratchpad.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi-ooxml.version}</version>
</dependency>
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>xdocreport</artifactId>
<version>${xdocreport.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>${poi-ooxml-schemas.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>ooxml-schemas</artifactId>
<version>${ooxml-schemas.version}</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>${jsoup.version}</version>
</dependency>
word转html,对于word2003和word2007转换方式不一样,因为word2003和word2007的格式不一样,工具类如下:
/**
* @author ismallboy
* @date 2020/2/19
*/
@Component
public class WordToHtmlUtil {
@Autowired
private UploadFileUtil uploadFileUtil;
/**
* 将word2003转换为html文件
*
* @param input
* @param bucket
* @throws IOException
* @throws TransformerException
* @throws ParserConfigurationException
*/
public String Word2003ToHtml(InputStream input, String bucket, String directory, String visitPoint)
throws IOException, TransformerException, ParserConfigurationException {
HWPFDocument wordDocument = new HWPFDocument(input);
WordToHtmlConverter wordToHtmlConverter = new WordToHtmlConverter(
DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument());
wordToHtmlConverter.setPicturesManager(new PicturesManager() {
@Override
public String savePicture(byte[] content, PictureType pictureType, String suggestedName, float widthInches,
float heightInches) {
String fileName = AliOssUtil.generateImageFileName() + suggestedName.substring(suggestedName.lastIndexOf(&#34;.&#34;));
return uploadFileUtil.uploadFile(content, bucket, directory, fileName, visitPoint);
}
});
// 解析word文档
wordToHtmlConverter.processDocument(wordDocument);
Document htmlDocument = wordToHtmlConverter.getDocument();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
OutputStream outStream = new BufferedOutputStream(baos);
DOMSource domSource = new DOMSource(htmlDocument);
StreamResult streamResult = new StreamResult(outStream);
TransformerFactory factory = TransformerFactory.newInstance();
Transformer serializer = factory.newTransformer();
serializer.setOutputProperty(OutputKeys.ENCODING, &#34;utf-8&#34;);
serializer.setOutputProperty(OutputKeys.INDENT, &#34;yes&#34;);
serializer.setOutputProperty(OutputKeys.METHOD, &#34;html&#34;);
serializer.transform(domSource, streamResult);
String content = baos.toString();
baos.close();
return content;
}
/**
*
* 2007版本word转换成html
*
* @param input
* @param bucket
* @param directory
* @param visitPoint
* @return
* @throws IOException
*/
public String Word2007ToHtml(InputStream input, String bucket, String directory, String visitPoint)
throws IOException {
XWPFDocument document = new XWPFDocument(input);
// 2) 解析 XHTML配置 (这里设置IURIResolver来设置图片存放的目录)
XHTMLOptions options = XHTMLOptions.create();
Map<String, String> imgMap = new HashMap<>();
options.setExtractor(new IImageExtractor() {
@Override
public void extract(String imagePath, byte[] imageData) throws IOException {
//获取图片数据并且上传
String fileName = AliOssUtil.generateImageFileName() + imagePath.substring(imagePath.lastIndexOf(&#34;.&#34;));
String imgUrl = uploadFileUtil.uploadFile(imageData, bucket, directory, fileName, visitPoint);
imgMap.put(imagePath, imgUrl);
}
});
// html中图片的路径 相对路径
options.URIResolver(new IURIResolver() {
@Override
public String resolve(String uri) {
//设置图片路径
return imgMap.get(uri);
}
});
options.setIgnoreStylesIfUnused(false);
options.setFragment(true);
// 3) 将 XWPFDocument转换成XHTML
ByteArrayOutputStream baos = new ByteArrayOutputStream();
XHTMLConverter.getInstance().convert(document, baos, options);
String content = baos.toString();
baos.close();
return content;
}
}使用方法如下:
ublic String uploadSourceNews(MultipartFile file) {
String fileName = file.getOriginalFilename();
String suffixName = fileName.substring(fileName.lastIndexOf(&#34;.&#34;));
if (!&#34;.doc&#34;.equals(suffixName) && !&#34;.docx&#34;.equals(suffixName)) {
throw new UploadFileFormatException();
}
DateTimeFormatter formatter = DateTimeFormatter.ofPattern(&#34;yyyyMM&#34;);
String dateDir = formatter.format(LocalDate.now());
String directory = imageDir + &#34;/&#34; + dateDir + &#34;/&#34;;
String content = null;
try {
InputStream inputStream = file.getInputStream();
if (&#34;doc&#34;.equals(suffixName)) {
content = wordToHtmlUtil.Word2003ToHtml(inputStream, imageBucket, directory, Constants.HTTPS_PREFIX + imageVisitHost);
} else {
content = wordToHtmlUtil.Word2007ToHtml(inputStream, imageBucket, directory, Constants.HTTPS_PREFIX + imageVisitHost);
}
} catch (Exception ex) {
logger.error(&#34;word to html exception, detail:&#34;, ex);
return null;
}
return content;
}关于doc和docx的一些存储格式介绍:
docx 是微软开发的基于 xml 的文字处理文件。docx 文件与 doc 文件不同, 因为 docx 文件将数据存储在单独的压缩文件和文件夹中。早期版本的 microsoft office (早于 office 2007) 不支持 docx 文件, 因为 docx 是基于 xml 的, 早期版本将 doc 文件另存为单个二进制文件。
DOCX is an XML based word processing file developed by Microsoft. DOCX files are different than DOC files as DOCX files store data in separate compressed files and folders. Earlier versions of Microsoft Office (earlier than Office 2007) do not support DOCX files because DOCX is XML based where the earlier versions save DOC file as a single binary file.
可能你会问了,明明是docx结尾的文档,怎么成了xml格式了?
很简单:你随便选择一个docx文件,右键使用压缩工具打开,就能得到一个这样的目录结构:
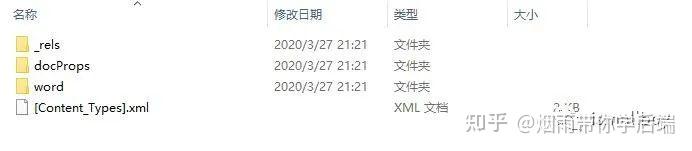
所以你以为docx是一个完整的文档,其实它只是一个压缩文件。
java 面试准备
准确的说这里又分为两部分:
1、Java 刷题
2、算法刷题
Java 刷题:此份文档详细记录了千道面试题与详解;
! 私信我回复【03】即可免费获取
很多人感叹“学习无用”,实际上之所以产生无用论,
是因为自己想要的与自己所学的匹配不上,这也就意味着自己学得远远不够。无论是学习还是工作,
都应该有主动性,所以如果拥有大厂梦,那么就要自己努力去实现它。
以上学习资料均免费放送,最后祝愿各位顺利拿到心仪的offer

小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。如果在阅读过程中有疑问,请留言讨论
作者:ismallboy
原文出处;java后端实现word上传并转html格式 - ismallboy - 博客园 |
|



 发表于 2022-9-23 22:11:11
发表于 2022-9-23 22:11:11