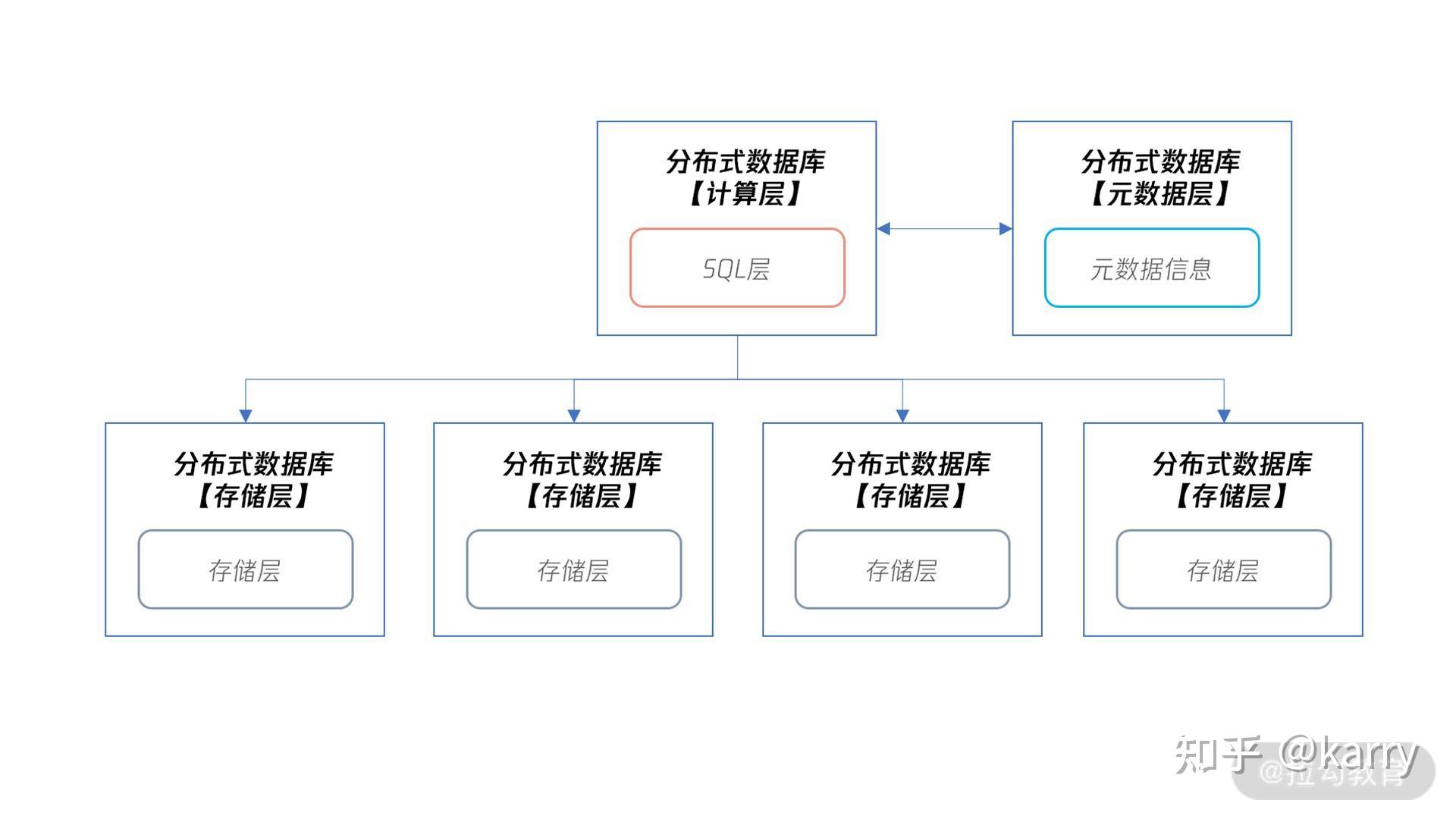
Wiki 官方对分布式数据库的定义为:
A distributed database is a database in which data is stored across different physical locations. It may be stored in multiple computers located in the same physical location (e.g. a data centre); or maybe dispersed over a network of interconnected computers.
接下来,我们看一看分布式 MySQL 数据库的整体架构。
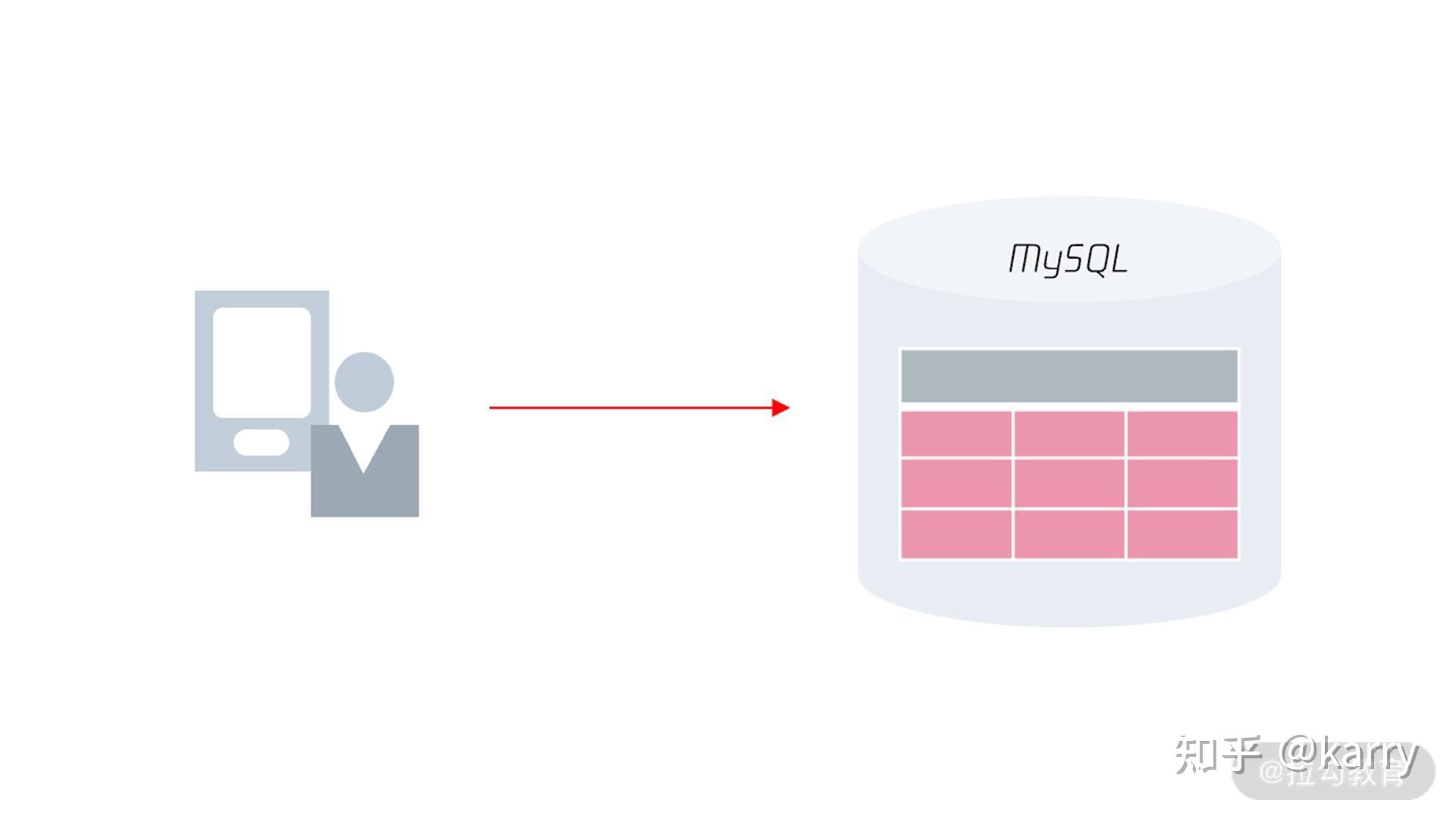
在学习分布式 MySQL 架构前,我们先看一下原先单机 MySQL 架构是怎样的。
可以看到,原先客户端是通过 MySQL 通信协议访问 MySQL 数据库,MySQL 数据库会通过高可用技术做多副本,当发生宕机进行切换。
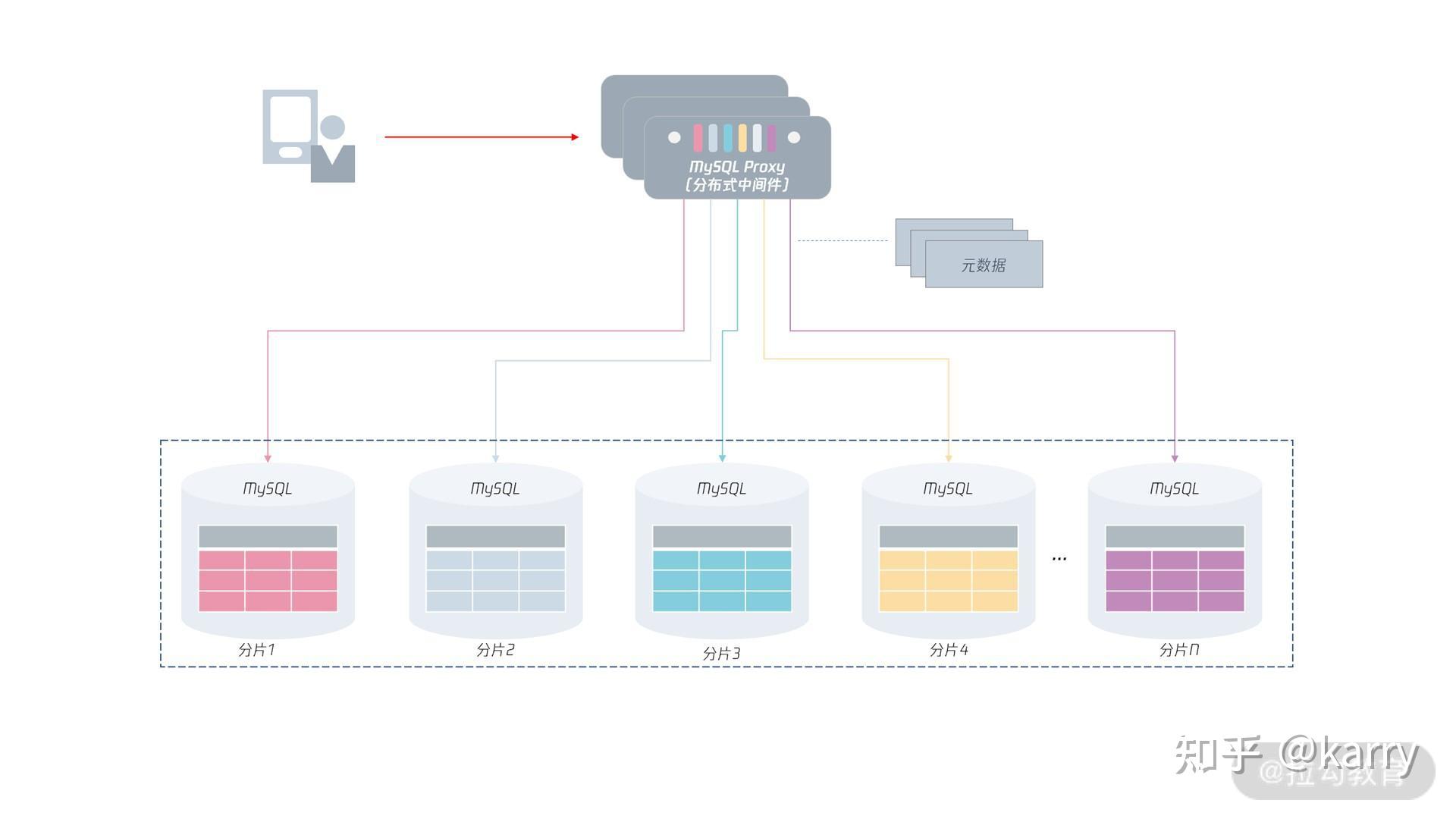
那么对于分布式 MySQL 数据库架构,其整体架构如下图所示:
从上图可以看到,这时数据将打散存储在下方各个 MySQL 实例中,每份数据叫“分片(Shard)”。
在分布式 MySQL 架构下,客户端不再是访问 MySQL 数据库本身,而是访问一个分布式中间件。
这个分布式中间件的通信协议依然采用 MySQL 通信协议(因为原先客户端是如何访问的MySQL 的,现在就如何访问分布式中间件)。分布式中间件会根据元数据信息,自动将用户请求路由到下面的 MySQL 分片中,从而将存储存取到指定的节点。
另外,分布式 MySQL 数据库架构的每一层都要由高可用,保证分布式数据库架构的高可用性。
对于上层的分布式中间件,是可以平行扩展的:即用户可以访问多个分布式中间件,如果其中一个中间件发生宕机,那么直接剔除即可。
因为分布式中间件是无状态的,数据保存在元数据服务中,它的高可用设计比较容易。
对于元数据来说,虽然它的数据量不大,但数据非常关键,一旦宕机则可能导致中间件无法工作,所以,元数据要通过副本技术保障高可用。
最后,每个分片存储本身都有副本,通过我们之前学习的高可用技术,保证分片的可用性。也就是说,如果分片 1 的 MySQL 发生宕机,分片 1 的从服务器会接替原先的 MySQL 主服务器,继续提供服务。
但由于使用了分布式架构,那么即使分片 1 发生宕机,需要 60 秒的时间恢复,这段时间对于业务的访问来说,只影响了 1/N 的数据请求。
可以看到,分布式 MySQL 数据库架构实现了计算层与存储层的分离,每一层都可以进行 Scale Out 平行扩展,每一层又通过高可用技术,保证了计算层与存储层的连续性,大大提升了MySQL 数据库的性能和可靠性,为海量互联网业务服务打下了坚实的基础。
感兴趣的话,可以关注下完整的内容,我将通过表结构设计、索引设计、高可用架构设计、分布式架构设计,由浅入深、循序渐进地与你一起打造出一个能支撑海量的并发访问的分布式 MySQL 架构。
同时欢迎关注<拉勾教育>,每天进步,与君共勉!



 发表于 2022-12-21 20:48:41
发表于 2022-12-21 20:48:41