|
|
本篇文章主要胡侃了一下 MySQL 执行一条 SQL 查询语句的基本流程
首先,介绍 MySQL 的三层逻辑架构,以及 MySQL 查询执行路径。然后,重点剖析执行一条 SQL 查询语句的详细步骤
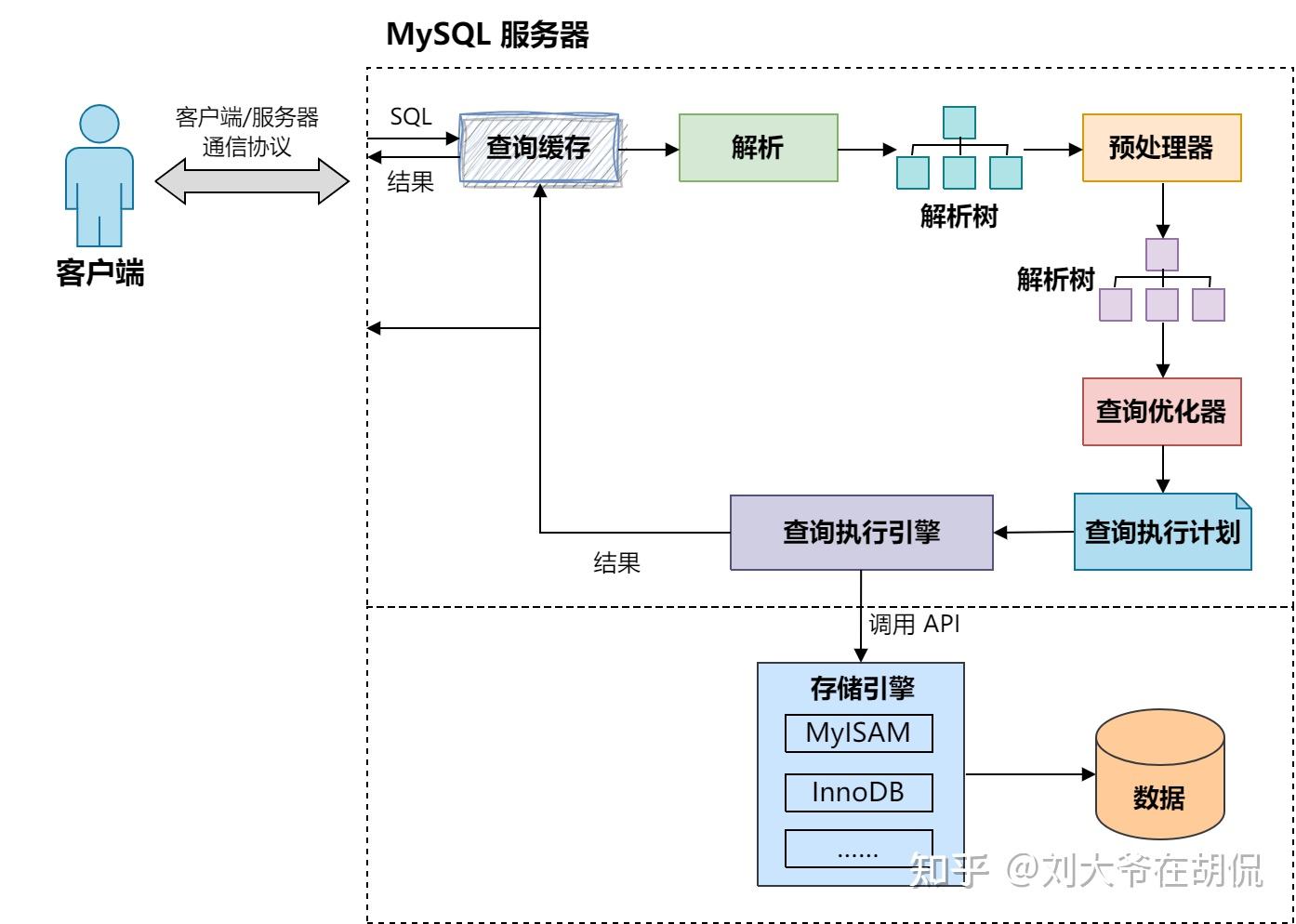
MySQL 查询执行路径
一、MySQL 的逻辑架构
- 第一层(连接层)的客户端所包含的服务并不是 MySQL 所独有的,大多数基于网络的客户端/服务器工具或服务器都有类似的架构。包括连接处理、身份验证、确保安全性等
- 第二层(服务层)架构大多数是 MySQL 的核心服务功能,包括查询解析、分析、优化以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等
- 第三层(引擎层)包含了存储引擎,存储引擎负责 MySQL 中数据的存储和提取。服务器通过存储引擎 API 进行通信,这些 API 屏蔽了不同存储引擎之间的差异,使得它们对上层的查询层基本是透明的。但存储引擎不会去解析 SQL , 不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求
二、MySQL 查询执行路径
- 客户端发送一条 SQL 查询语句给服务器
- 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果;否则进入下一阶段(MySQL 8.0 移除了查询缓存功能)
- 服务器端进行 SQL 解析、预处理,再由优化器生成对应的执行计划
- MySQL 根据优化器生成的执行计划,调用存储引擎的 API 来执行查询
- 将结果返回给客户端
1、MySQL 客户端/服务器通信协议
- MySQL 客户端和服务器之间的通信协议是“半双工”的,这意味着,在任何时刻,要么是由服务器向客户端发送数据,要么是由客户端向服务器发送数据,这两个动作不能同时发生
- MySQL 客户端/服务器通信协议的一个明显限制是,没法进行流量控制。一旦一端开始发生消息,另一端要接收完整个消息才能响应它
- MySQL 通常需要等所有的数据都已经发送给客户端才能释放这条查询所占用的资源,当返回一个很大的结果集时,耗时较大
2、查询缓存
- 在解析一个查询语句之前,如果查询缓存是打开的,MySQL 会优先检查这个查询是否命中查询缓存中的数据——通过一个对大小写敏感的哈希查找实现的。查询和缓存中的查询即使只有一个字节不同,那也不会匹配缓存结果,这种情况下查询就会进入下一阶段的处理
- 如果当前的查询命中了查询缓存,在返回查询结果之前 MySQL 会检查一次用户权限——这无须解析查询 SQL 语句,因为在查询缓存中已经存放了当前查询需要访问的表信息。如果权限没有问题,MySQL 会跳过所有其他阶段,直接从缓存中拿到结果并返回给客户端
- MySQL 8.0 移除了查询缓存功能
3、查询优化处理
- 如果查询没有命中缓存,会将一个 SQL 查询转换成一个执行计划,MySQL 再依照这个执行计划和存储引擎进行交互
- 本阶段包括多个子阶段:解析 SQL、预处理、优化 SQL 执行计划。这个过程中任何错误(例如语法错误)都可能终止查询
(1)语法解析器和预处理
- MySQL 通过关键字将 SQL 语句进行解析,并生成一棵对应的“解析树”。MySQL 解析器将使用 MySQL 语法规则验证和解析查询。例如,验证是否使用错误的关键字,使用关键字的顺序是否正确,引号是否能前后正确匹配
- 然后,预处理器检查生成的解析树,以查找解析器无法解析的其他语义。例如,检查数据表和数据列是否存在,解析名字和别名看是否有歧义
- 下一步,预处理器会验证权限
(2)查询优化器
- 语法树被认为是合法后,由优化器将其转化成查询执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划
- MySQL 使用基于成本的优化器,它将尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个
- 与成本有关的因素:每个表或者索引的页面个数、索引的基数(索引中不同值的数量)、索引和数据行的长度、索引分布情况。优化器在评估成本时,并不考虑任何层面的缓存带来的影响,它假设读取任何数据都需要一次磁盘 I/O
4、查询执行引擎
- 在解析和优化阶段,MySQL 将生成查询对应的执行计划(是一个数据结构),MySQL 的查询执行引擎会根据这个执行计划来完成整个查询
- 查询执行阶段,MySQL 根据执行计划给出的指令逐步执行。在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成
- 存储引擎接口有着非常丰富的功能,但是底层接口却只有几十个,这些接口像“搭积木”一样能够完成查询的大部分操作。例如,有一个查询某个索引的第一行的接口,再有一个查询某个索引条目的下一个条目的功能,有了这两个功能就可以完成全索引扫描的操作了。这种简单的接口模式,让 MySQL 的存储引擎插件式架构成为可能
5、将结果返回给客户端
- 即使查询不需要返回结果集给客户端,MySQL 仍然会返回这个查询的一些信息,例如该查询影响到的行数
- 如果查询可以被缓存,那么 MySQL 在这个阶段也会将结果存放到查询缓存中
- MySQL 将结果集返回客户端是一个增量、逐步返回的过程。例如,在连接操作中,一旦服务器处理完最后一个连接表,开始生成第一条结果时,MySQL 就可以开始向客户端逐步返回结果集了。这样,服务器端无须存储太多的结果,也就不会因为要返回太多结果而消耗太多内存。另外,也让 MySQL 客户端第一时间获得返回的结果
- 结果集中的每一行都会以一个满足 MySQL 客户端/服务器通信协议的封包发送,再通过 TCP 协议进行传输。在 TCP 传输的过程中,可能对 MySQL 的封包进行缓存然后批量传输
|
|



 发表于 2023-6-9 13:13:24
发表于 2023-6-9 13:13:24