|
|
各位是不是也和喵小 DI 一样在深入研究强化学习呢?那么请一定不要错过我们最新公布的 repo: awesome-RLHF ,这个 repo 致力于帮大家整理收录基于人类反馈的强化学习的前沿研究进展,从而让任何感兴趣的人都能更好地了解此领域。
欢迎体验 Awesome-RLHF :
https://github.com/opendilab/awesome-RLHF
关于RLHF
Reinforcement Learning with Human Feedback(RLHF)是强化学习(RL)的一个扩展分支,当决策问题的优化目标比较抽象,难以形式化定义具体的奖励函数时,RLHF 系列方法可以将人类的反馈信息纳入到训练过程,通过使用这些反馈信息构建一个奖励模型神经网络,以此提供奖励信号来帮助 RL 智能体学习,从而更加自然地将人类的需求,偏好,观念等信息以一种交互式的学习方式传达给智能体,对齐(align)人类和人工智能之间的优化目标,产生行为方式和人类价值观一致的系统。
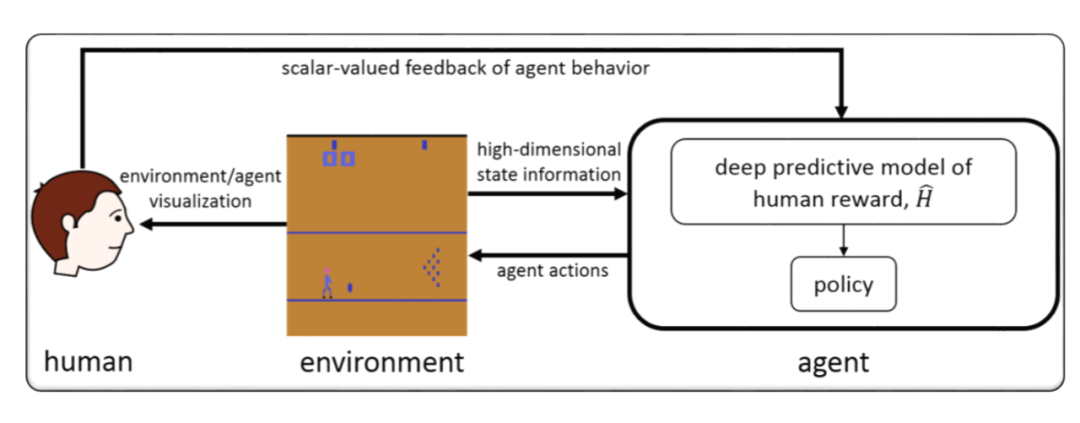
最初,在 2017 年的研究工作《Deep reinforcement learning from human preferences》[1] 中就有研究者尝试将人类反馈信息引入 Atari [2] 、MuJoCo [3] 这样的经典决策学术环境,从而取得了一些有趣的发现。后来,相关内容又进一步衍生出 preference-based RL/Inverse RL [4] 等研究子方向。
从 2020 年起至今,研究者们又进一步发现对于大语言模型(Large Language Model,LLM),RLHF 方法可以有效提升 LLM 生成质量的真实性和信息完整性,在 LLM 的输出和人类需要的对话信息之间架起一座桥梁 [5-6]。而在 2022 年末,ChatGPT [7] 的推出更是技惊四座,短短几个月内已经有超过一亿的用户尝试并领略到了这种强大对话系统的通用性和便利性。RLHF 成功将 LLM 内部蕴含的知识激发出来,高效地促进人工智能和人类偏好之间的同步与协调。
具体来说,RLHF 可能的优势有如下三点:
- 建立优化范式:为无法显式定义奖励函数的决策任务,建立新的优化范式。对于需要人类偏好指引的机器学习任务,探索出一条可行且较高效的交互式训练学习方案。
- 省数据(Data-Efficient):相对其他的训练方法,例如监督学习,Top-K 采样等,RLHF 能够利用更少的人类反馈数据达到相近的训练效果。
- 省参数(Parameter-Efficient):相对其他的训练方法,例如监督学习,Top-K 采样等,RLHF 可以让参数量较小的神经网络也能发挥出强大的性能。
精选论文
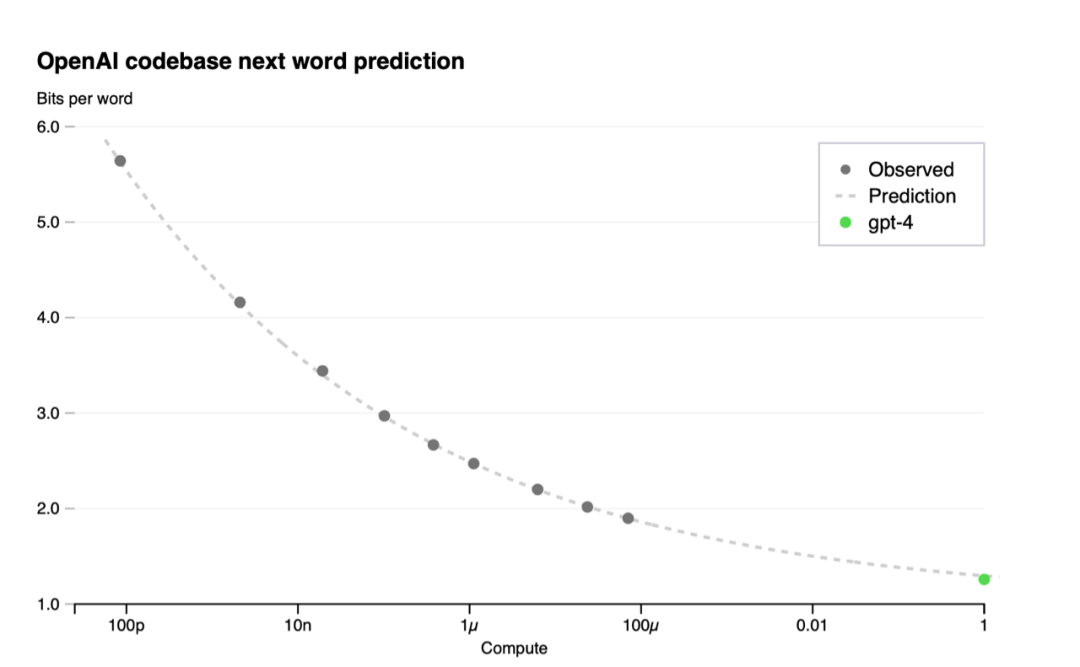
论文标题:GPT-4 Technical Report
作者:OpenAI
链接:https://cdn.openai.com/papers/gpt-4.pdf
关键词:A large-scale, multimodal model, Transformer based model, Fine-tuned used RLHF
论文标题:Better Aligning Text-to-Image Models with Human Preference
作者:Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
链接:https://arxiv.org/abs/2303.14420
关键词:Diffusion Model, Text-to-Image, Aesthetic

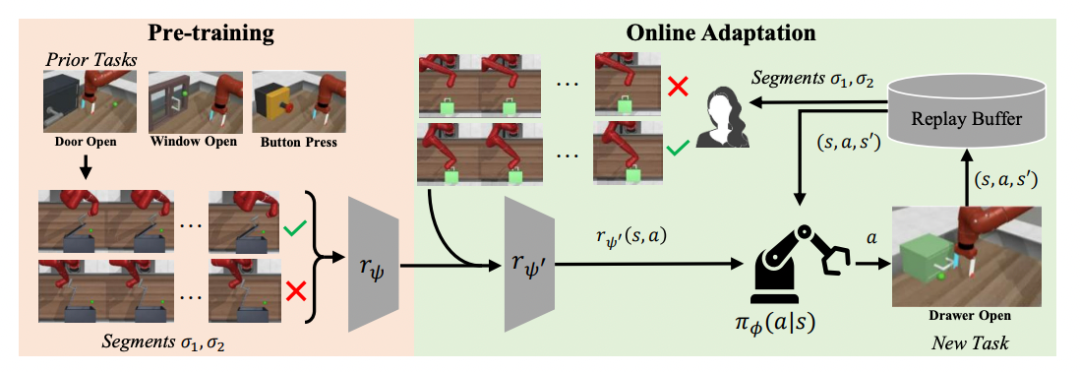
论文标题:Few-shot Preference Learning for Human-in-the-Loop RL
作者:Joey Hejna, Dorsa Sadigh
链接:https://openreview.net/pdf?id=IKC5TfXLuW0
关键词:Preference Learning, Interactive Learning, Multi-task Learning, Expanding the pool of available data by viewing human-in-the-loop RL
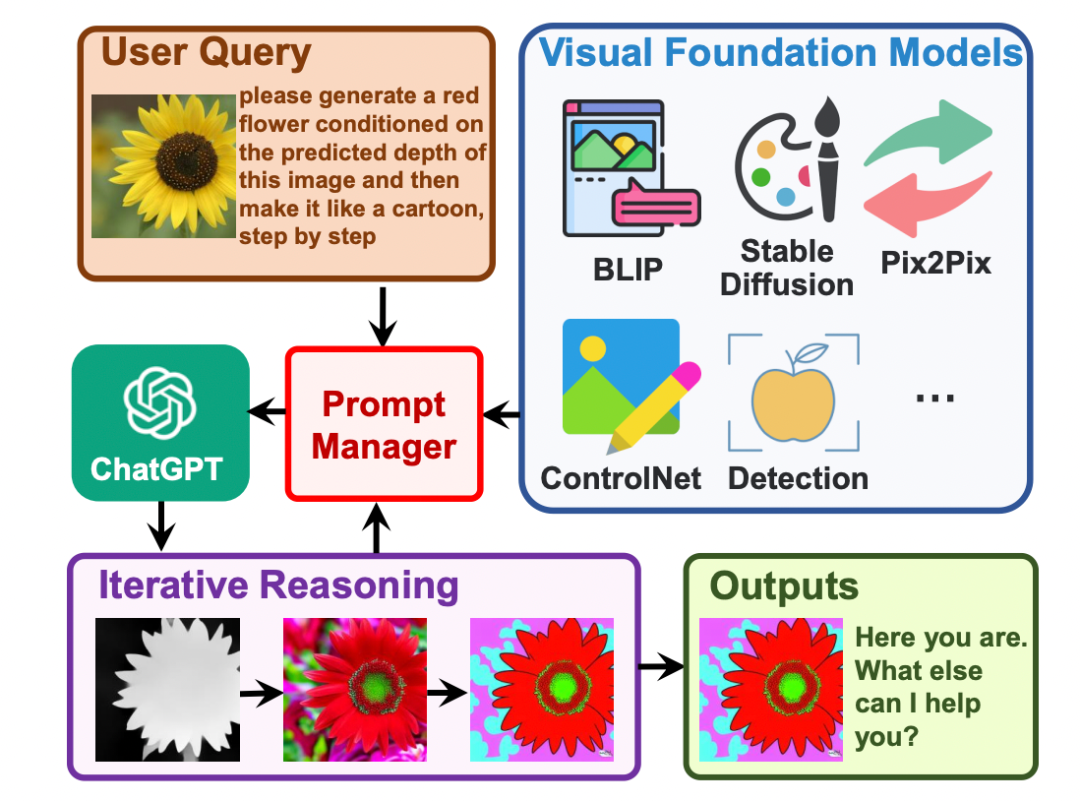
论文标题:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
作者:Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
链接:https://arxiv.org/pdf/2303.04671.pdf
关键词:Visual Foundation Models, Visual ChatGPT
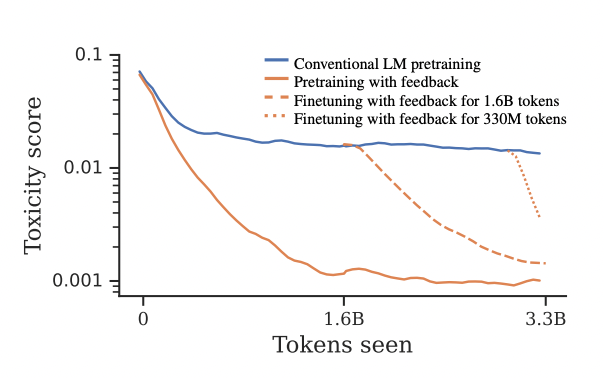
论文标题:Pretraining Language Models with Human Preferences (PHF)
作者:Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
链接:https://arxiv.org/abs/2302.08582
关键词: Pretraining, offline RL, Decision transformer
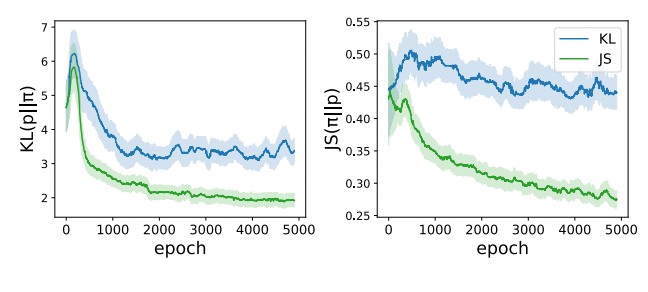
论文标题:Aligning Language Models with Preferences through f-divergence Minimization (f-DPG)
作者:Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
链接:https://arxiv.org/abs/2302.08215
关键词:f-divergence, RL with KL penalties
参考文献
[1] Christiano P F, Leike J, Brown T, et al. Deep reinforcement learning from human preferences[J]. Advances in neural information processing systems, 2017, 30.
[2] https://gymnasium.farama.org/environments/atari/
[3] https://gymnasium.farama.org/environments/mujoco/
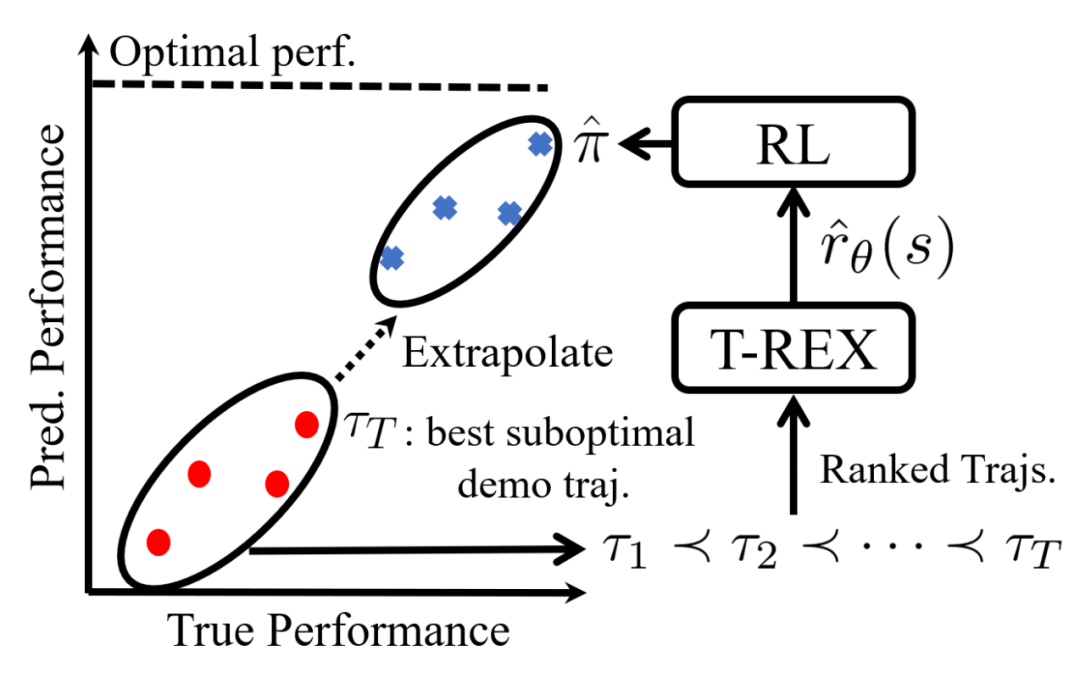
[4] Brown D, Goo W, Nagarajan P, et al. Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations[C]//International conference on machine learning. PMLR, 2019: 783-792.
[5] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
[6] Ramamurthy R, Ammanabrolu P, Brantley K, et al. Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization[J]. arXiv preprint arXiv:2210.01241, 2022.
[7] https://openai.com/blog/chatgpt |
|



 发表于 2023-7-20 18:10:59
发表于 2023-7-20 18:10:59